NVIDIA4090GPU服务器部署ChatGLM3-6B教程

最近一直在体验ChatGLM2-6B,文章也写了一半。结果ChatGLM3突然发布了,于是又体验了ChatGLM3-6B。
本文只是记录部署的过程,以及测试使用功能。并未高深的内容!技术大佬可忽略!
简介
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。
ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
开源地址
https://github.com/THUDM/ChatGLM3
准备工作
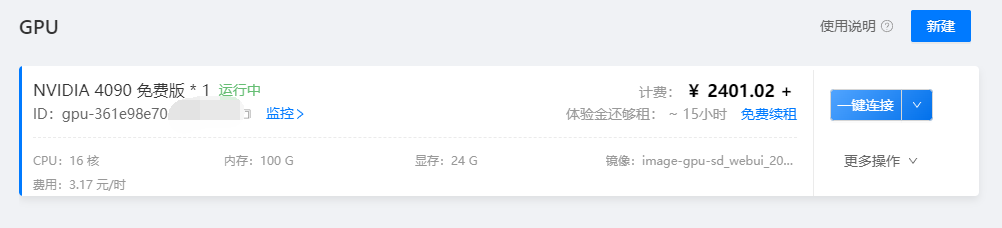
GPU服务器,显存最少13G以上
FRP内网穿透(由于服务器并未开放其他端口,临时才有这种方式实现外网测试访问,如果官方提供外网端口可忽略)
机器配置
型号:NVIDIA 4090
CPU:16 核
内存:100 G
系统环境:ubuntu 22.04, nvidia_driver 530.30.02,miniconda py311_23.5.2-0,jupyterlab 4.0.4,stable-diffusion-webui 1.5.2
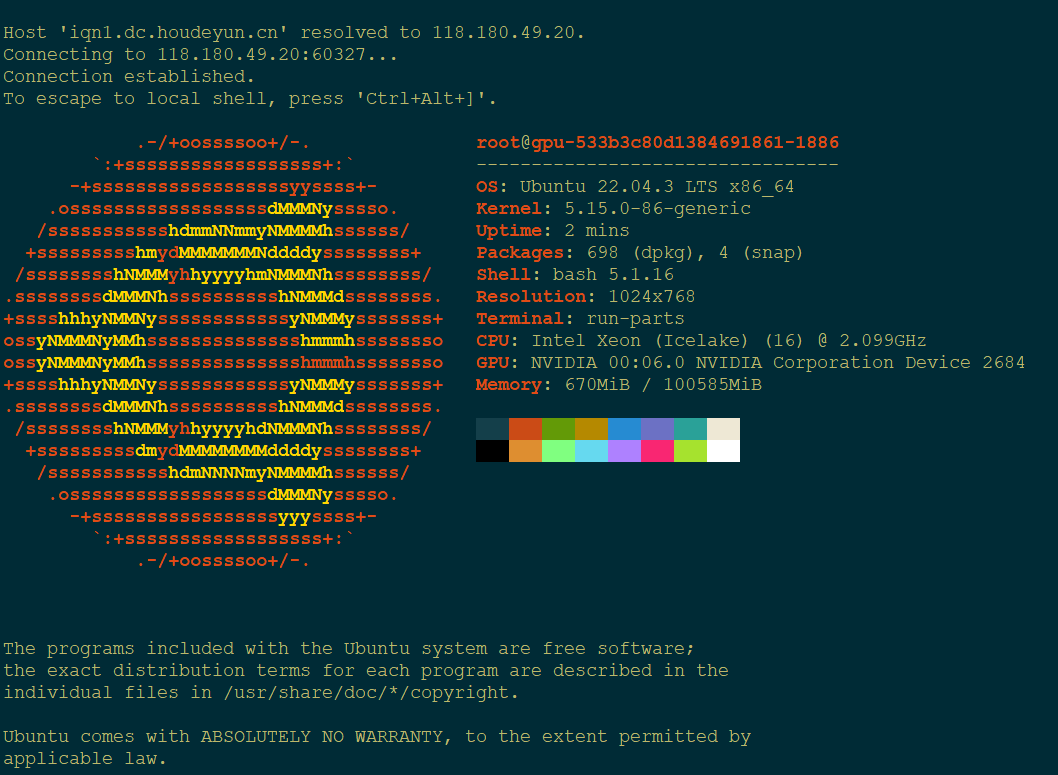
(base) root@gpu-4eaf390938734d30b61-1886:~/public# nvidia-smi
Tue Oct 31 10:40:56 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 On | 00000000:00:06.0 Off | Off |
| 0% 31C P8 22W / 450W| 1MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
环境部署
由于服务器自带部分依赖内容,本文不用安装!系统自带!
#首先需要下载本仓库(国内可能会出现无法访问,多试几次)
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
#使用 pip 安装依赖
pip install -r requirements.txt
其中 transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能。
模型下载
HuggingFace
境外服务器可直接从 Hugging Face Hub 下载模型需要先安装Git LFS,然后运行!
sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co/THUDM/chatglm3-6b
ModelScope
针对国内服务器只能采取这种方式才有这种方式下载模型,速度会快很多!!!
新建 download.py,粘贴以下内容
from modelscope import snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")执行命令:python download.py 开始下载模型

模型文件目录
模型默认会下载到:/root/.cache/modelscope/hub/ZhipuAI/chatglm3-6b
可以将模型文件迁移到其他目录!本文下面演示全部使用上面的地址。
启动服务
基础Demo
修改模型文件目录
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
from utils import load_model_on_gpus
#修改这里模型文件目录
model_path = "/root/.cache/modelscope/hub/ZhipuAI/chatglm3-6b"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).cuda()
修改文件最后一行,share=True
demo.queue().launch(share=True, server_port=8501, inbrowser=True)
启动服务:

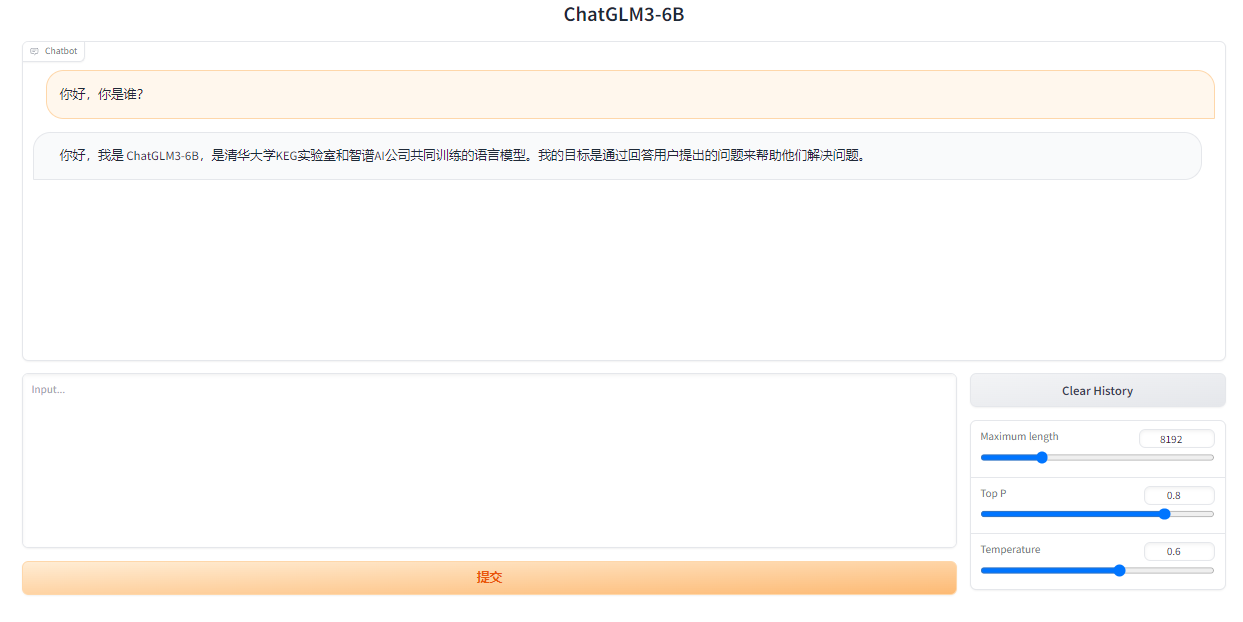
策略参数
Top P:限制最高置信度分数,即在回答问题时,助手最多可以给出多少置信度较高的答案
Maximum length:文本的最大长度,即助手能够回答的最大字符数
Temperature:参数是控制助手回答的随机性,即在回答问题时,助手的回答可能会更加随机的
部分模型支持惩罚机制
Frequency penalty 和 Presence penalty 是两种惩罚机制,用于限制人工智能模型在对话中的回复频率和连续时间。
Frequency penalty 是指在对话中,如果人工智能模型连续回复了多个问题,那么后续问题回答的频率会降低。具体来说,如果模型在一段时间内连续回答了 n 个问题,那么第 n+1 个问题回答的频率会变为之前的1/2,第 n+2 个问题回答的频率会变为之前的1/4,以此类推。这种惩罚机制旨在避免模型过度依赖之前的回答,影响后续问题的回答质量。
Presence penalty 是指在对话中,如果人工智能模型在一段时间内没有回答问题,那么后续问题回答的频率也会降低。具体来说,如果模型在一段时间内没有回答问题,那么第n个问题回答的频率会变为0,直到模型再次回答问题。这种惩罚机制旨在鼓励模型在对话中保持一定的活跃度,避免模型过长时间地保持沉默,影响后续问题的回答质量。
OpenAI Demo
修改 openai_api_demo/openai_api.py
修改模型文件地址
if __name__ == "__main__":
model_path = "/root/.cache/modelscope/hub/ZhipuAI/chatglm3-6b"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).cuda()
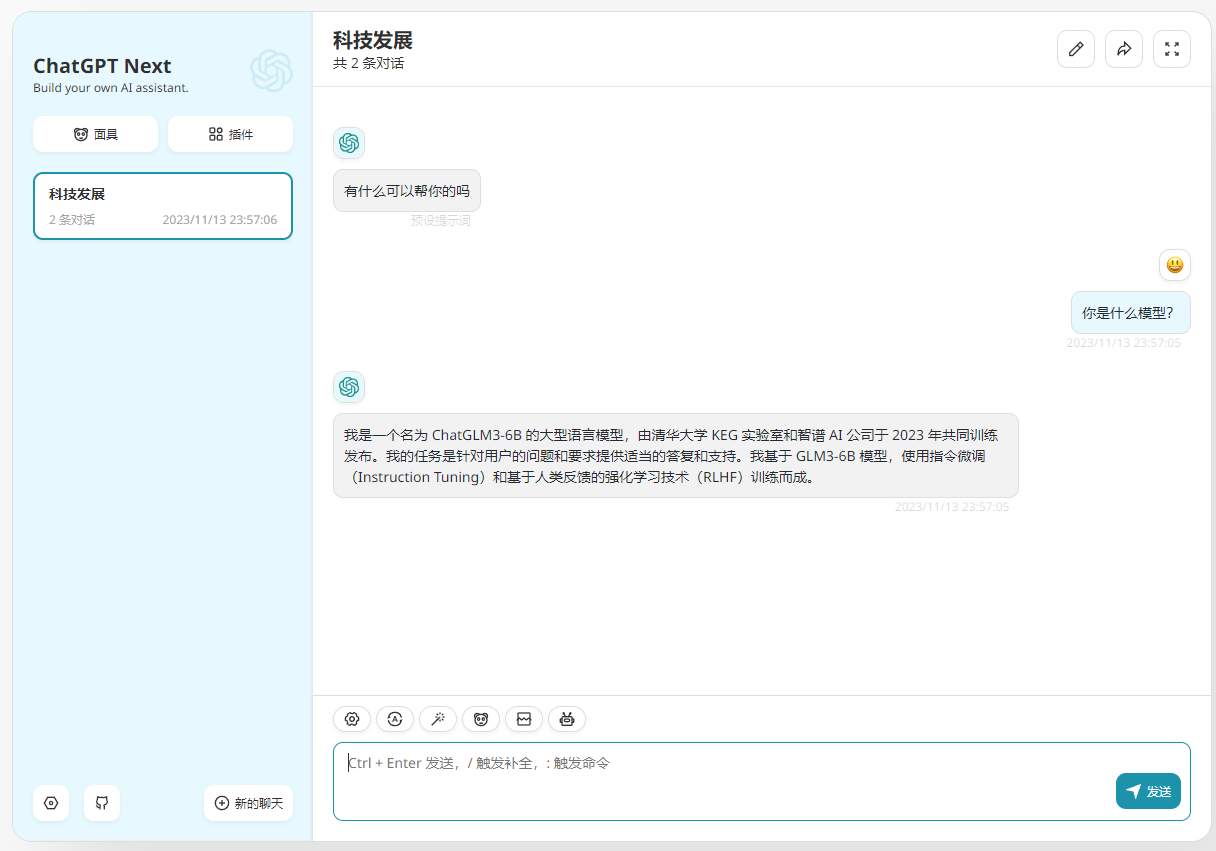
部署ChatGPT Next
docker pull yidadaa/chatgpt-next-web docker run -d -p 3000:3000 yidadaa/chatgpt-next-web
ChatGPT Next 设置 - 选择自定义接口 - 接口地址 填写

综合Demo
conda create -n chatglm3-demo python=3.10
conda activate chatglm3-demo
#安装依赖
pip install -r requirements.txt
#使用 Code Interpreter 还需要安装 Jupyter 内核
ipython kernel install --name chatglm3-demo --user
#环境变量,指定模型文件地址
export MODEL_PATH=/path/to/model
#启动服务
streamlit run main.py

访问Demo
- Chat: 对话模式,在此模式下可以与模型进行对话。
- Tool: 工具模式,模型除了对话外,还可以通过工具进行其他操作。
- Code Interpreter: 代码解释器模式,模型可以在一个 Jupyter 环境中执行代码并获取结果,以完成复杂任务。
对话模式
Chat (对话模式)不多介绍
工具模式
在composite_demo目录中文件:tool_registry.py 中定义自己的工具方法。
官方提供了2个方法:get_weather (获取城市气候),random_number_generator(生成随机数)
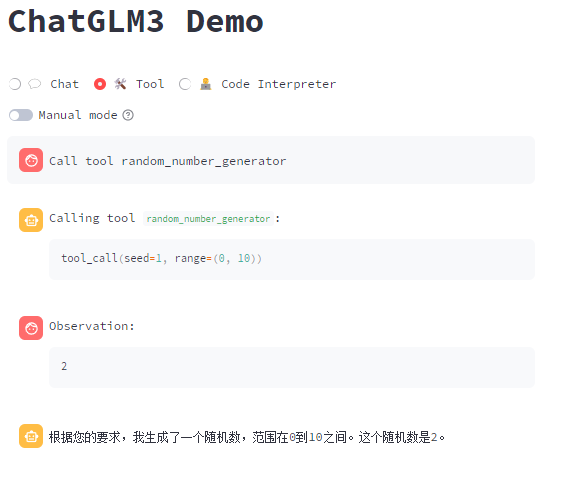
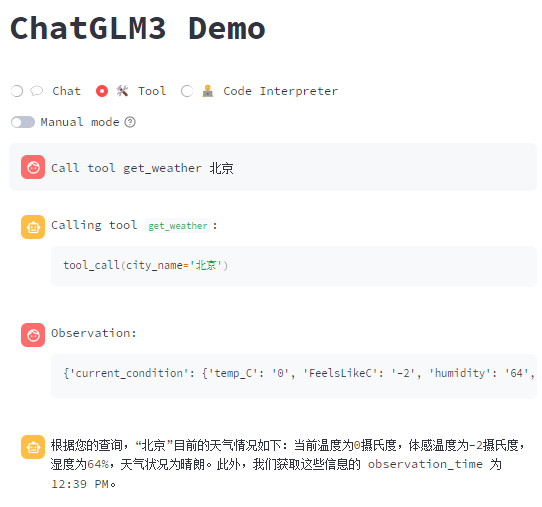
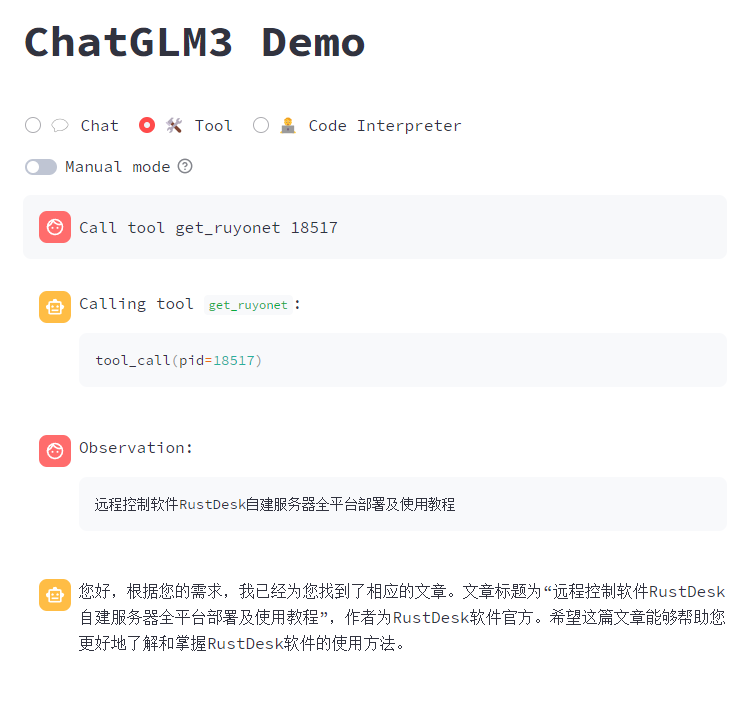
如何自定义工具,同样在 tool_registry.py 填写自己的代码,通过文章ID 获取文章的标题!
@register_tool
def get_ruyonet(
pid: Annotated[int, '输入文章ID', True],
) -> str:
"""
通过文章ID获取文章内容
"""
ret = ""
import requests
from bs4 import BeautifulSoup
try:
response = requests.get(f"https://51.RUYO.net/{pid}.html")
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
ret = soup.find('h1').text
except:
import traceback
ret = "Error encountered while fetching ruyonet data!\n" + traceback.format_exc()
return str(ret)
重启服务后,测试一下!
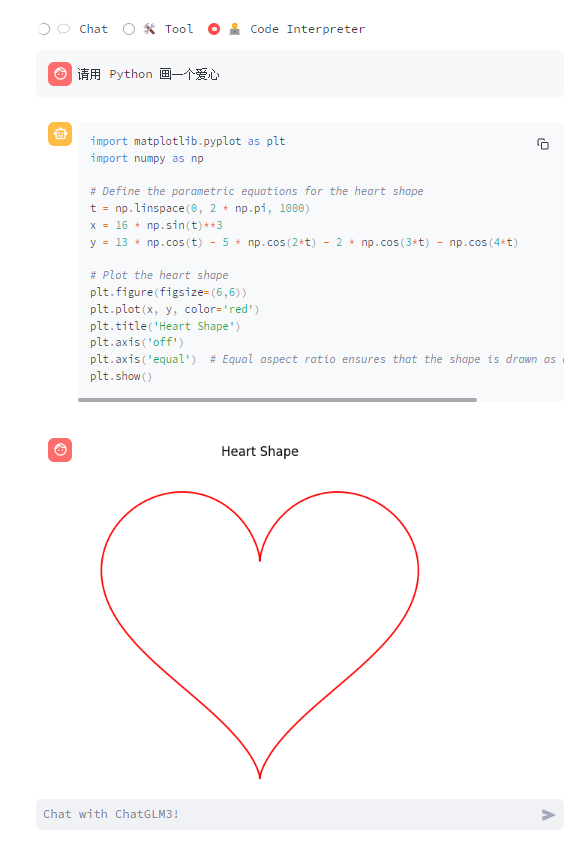
代码解释器模式
个人测试感觉,只有像官方那样画爱心貌似还行。画个其他的貌似都不行。
运行监测
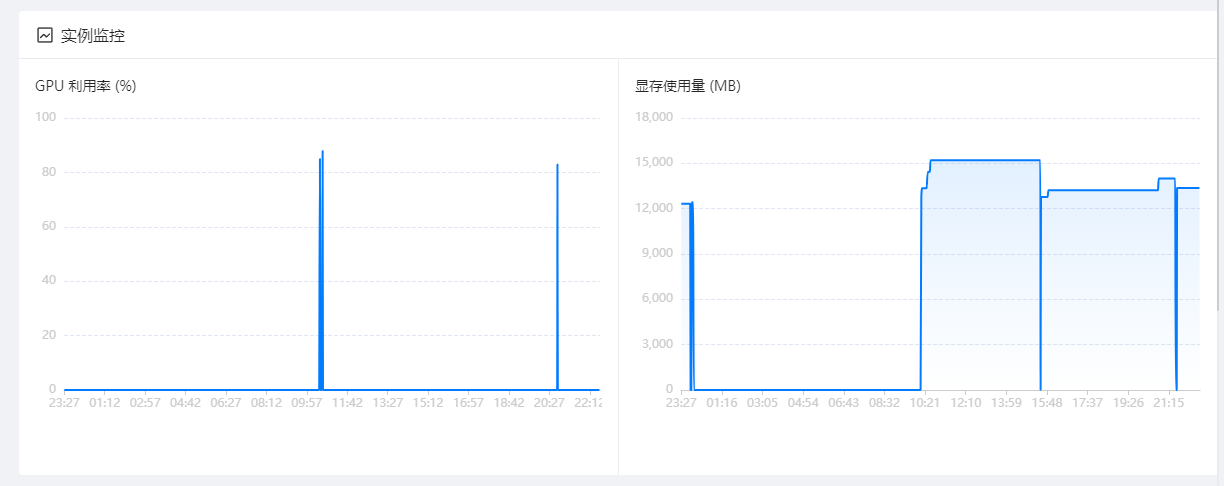
服务器显存正常运行在13G - 15G之间波动。
GPU利用率波动不大。
未完待续
业余时间一边体验功能,一边水文章。关于ChatGLM3微调,LangChain部分内容 还没有顺利体验完成,后续再水文章更新吧。
有童鞋问,弄这些有何用?其实作为一个新时代的农民工,要尽量跟具有革命意义的技术变革。不是所有人需要了解内部运行逻辑,但是对于 "农民工" 应该最起码需要知道怎么使用它。
有任何问题,大家可留言讨论!!







